Implementation
We used Baxter's left-hand camera to view the table and the right hand to grasp and move the objects. After taking a picture of the desired configuration for all of the objects and then subsequently taking a picture of the desk in the disorganized state, the left hand moves out of the way to allow the right hand to pick up and move the objects to their desired locations.
Given the coordinates of each object and their respective destination coordinates, the right arm will move to a fixed height above the object, carefully lower the gripper to grab the object, and then move back up to fixed height before moving the object to its desired location so that it does not knock other objects over. In the edge case where two objects are swapped, the system will first check if the desired location is blocked. It checks if a location is blocked if there is an object within a fixed radius of the destination coordinates. If there is an object blocking the way, it will radially scan around that blocking object for an unoccupied space, move the blocking object temporarily to the unoccupied space, and then move the original object to its destination.
To train CNN for the object-detection, we firstly built our own dataset using the wood blocks, cardboard and the left-hand camera of Asimov the Baxter. We wrote a script which controls the ROS to manage the left-hand camera and capture images automatically at 60 fpm. We then put the wood blocks on a piece of cardboard and used the left-camera to capture about 500 frames of our scene with different objects in different locations. With the raw images that we took, we used LABELIMG, an annotation tool to label all the raw images. which contains coordinates of different objects.
After that, we set up the deep learning environment on a server with GPU, and used the Faster R-CNN to train our own neural networks. Note that we randomly set 80% for training and 20% data for testing. After finishing training the models, we tested our neural network on unseen Asimov test data and Archytas test data.
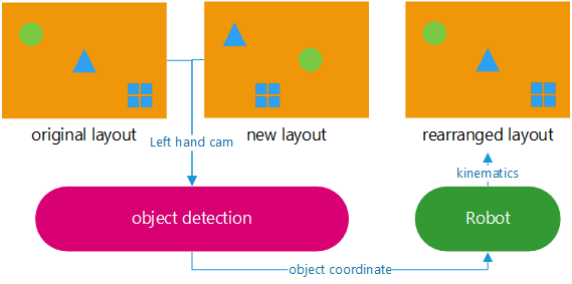
The diagram below illustrates a high-level explanation of how our project works:
Given the coordinates of each object and their respective destination coordinates, the right arm will move to a fixed height above the object, carefully lower the gripper to grab the object, and then move back up to fixed height before moving the object to its desired location so that it does not knock other objects over. In the edge case where two objects are swapped, the system will first check if the desired location is blocked. It checks if a location is blocked if there is an object within a fixed radius of the destination coordinates. If there is an object blocking the way, it will radially scan around that blocking object for an unoccupied space, move the blocking object temporarily to the unoccupied space, and then move the original object to its destination.
To train CNN for the object-detection, we firstly built our own dataset using the wood blocks, cardboard and the left-hand camera of Asimov the Baxter. We wrote a script which controls the ROS to manage the left-hand camera and capture images automatically at 60 fpm. We then put the wood blocks on a piece of cardboard and used the left-camera to capture about 500 frames of our scene with different objects in different locations. With the raw images that we took, we used LABELIMG, an annotation tool to label all the raw images. which contains coordinates of different objects.
After that, we set up the deep learning environment on a server with GPU, and used the Faster R-CNN to train our own neural networks. Note that we randomly set 80% for training and 20% data for testing. After finishing training the models, we tested our neural network on unseen Asimov test data and Archytas test data.
The diagram below illustrates a high-level explanation of how our project works:
1) Visualization of workspace
- Both arms are moved to their start positions. When the space is clear, the left arm equipped with a camera takes a top-down picture of our workspace.
- The desired positions of the objects relative to Baxter are calculated by either 1) the AR tag tracking or 2) the object recognition localization.
- The objects are then manually moved to new locations.
- The camera takes another image of the new state of the workspace and the objects are localized in the same way.
- Baxter moves the objects to their new locations one at a time. If an object's destination is blocked by another object, it will remove the obstruction and then proceed in moving the object.
